Building an AI Agent With Memory Using MongoDB, Fireworks AI, and LangChain





Rate this tutorial


This tutorial provides a step-by-step guide on building an AI research assistant agent that uses MongoDB as the memory provider, Fireworks AI for function calling, and LangChain for integrating and managing conversational components.
This agent can assist researchers by allowing them to search for research papers with semantic similarity and vector search, using MongoDB as a structured knowledge base and a data store for conversational history.
This repository contains all the steps to implement the agent in this tutorial, including code snippets and explanations for setting up the agent's memory, integrating tools, and configuring the language model to interact effectively with humans and other systems.
What to expect in this tutorial:
- Definitions and foundational concepts of an agent
- Detailed understanding of the agent's components
- Step-by-step implementation guide for building a research assistance agent
- Insights into equipping agents with effective memory systems and knowledge management
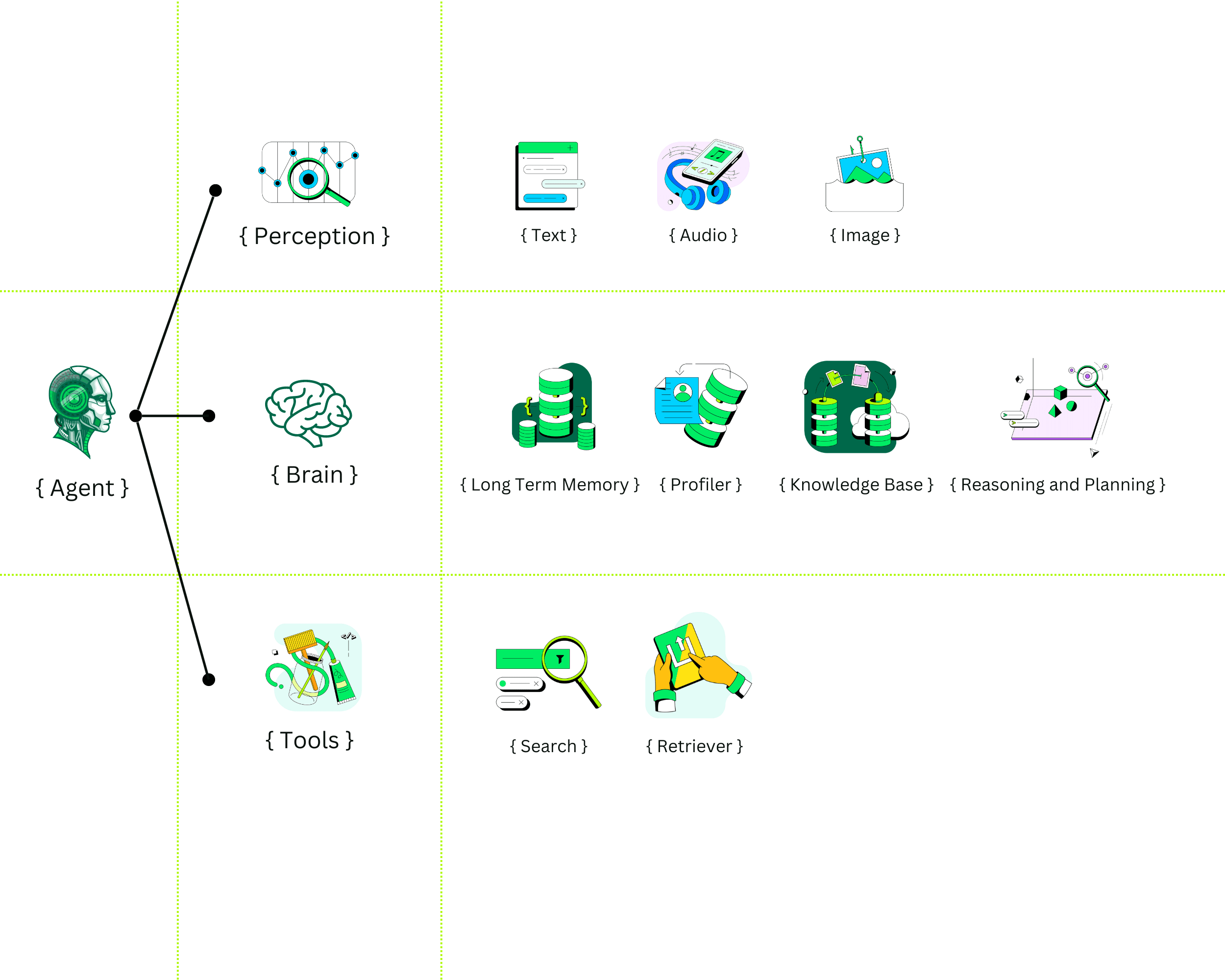
An agent is an artificial computational entity with an awareness of its environment. It is equipped with faculties that enable perception through input, action through tool use, and cognitive abilities through foundation models backed by long-term and short-term memory. Within AI, agents are artificial entities that can make intelligent decisions followed by actions based on environmental perception, enabled by large language models.

Before discussing the stack and implementation of an agent, it helps to understand the components and characteristics of the new form factor of AI applications. This section explores the key aspects of agents.
An agent is a computational entity composed of several integrated components, including the brain, perception, and action. These components work cohesively to enable the agent to achieve its objectives and goals.
- Brain: This component is crucial for the cognitive functions of an agent, such as reasoning, planning, and decision-making. This is implemented with an LLM. The brain consists of several modules: memory, profiler, and knowledge. The memory module stores past interactions, allowing the agent to utilize historical data for future planning and actions. The profiler module adapts the agent's behavior to fit defined roles, while the knowledge module stores and retrieves domain-specific information that assists in planning and action.
- Action: The action component allows the agent to react to its environment and new information. It includes modules that help the agent generate responses and interact with other systems. Using the brain's processes, an LLM-based agent can decompose tasks into steps, each associated with specific tools from the agent's arsenal, allowing for effective utilization at appropriate times.
- Perception: This component handles the capture and processing of inputs from the environment generated by humans and other agents. Inputs are primarily auditory, textual, and visual, which the agent processes to inform actions and decisions.
The agent implemented in this tutorial will have all three major components described above, including access to tools to aid the agent in achieving a defined goal.
LLM-based agents demonstrate behaviours and capabilities that enable them to perform complex tasks autonomously. Each characteristic equips agents with unique abilities, from decision-making and problem-solving to interacting dynamically with their environment and other entities.
Below is a summary of the key characteristics of agents:
- Agents are autonomous and independent.
- Agents are introspective and proactive.
- Agents are reactive.
- Agents are interactive.
Agents are autonomous and independent, with their actions and decisions driven by a clearly defined objective typically set by humans. However, their instructions do not specify the tools to use or steps to take, requiring agents to plan and reason independently. Language agents, enhanced by large language models, are particularly adept at using advanced planning and reasoning skills.
LLM-based agents are introspective and proactive. They can respond to stimuli using methodologies like ReAct and chain-of-thought prompting, which help them break down problems and plan actions effectively. These agents are also reactive, using tool use and input consumption abilities to act based on internal and external observations without external influence. This includes processing various forms of input, such as text, visual, and auditory data.
Furthermore, agents are highly interactive, often needing to communicate with other agents or humans within their systems. They can understand feedback and generate responses, which helps them adapt their actions accordingly. In multi-agent environments, their ability to assume roles and mimic societal behaviors facilitates collaboration and fulfills overarching objectives.
This section covers the tools and libraries used to build the agent designed for the specific use case of an AI research assistant.
The abilities of the AI research assistant are as follows:
- Provide a list of research papers related to topics and subjects from user queries.
- Supply research paper abstracts upon request.
- Utilize its knowledge base to retrieve metadata on stored research papers.
- Use this information to address user queries and achieve its objectives effectively.
Fireworks AI's FireFunction V1 enables the agent's brain to respond to user queries, decide when to use tools, and generate structured input for available tools. The agent's perception of its environment is enabled solely through text input. This component handles users' raw text inputs.
LLMs are capable of tool use, and the agent in this tutorial is focused on information retrieval via various methods.
Retriever and Arxiv Document Loader from LangChain implement tools to retrieve information. The agent uses the Retriever to search and fetch relevant information from a data store and the Arxiv Document Loader to access and retrieve scientific documents as needed..png&w=3840&q=75)
MongoDB is the agent's memory provider and provides long-term data storage and management for conversational history, a vector database for storing and retrieving vector embedding data, and data storage for the agent's operational data. MongoDB's vector search capabilities enable information retrieval based on semantic similarities between user queries and items in the vector database, which simulates the agent's inherent knowledge.
The first step in the implementation process is installing the necessary libraries to access classes, methods, and functionalities needed to implement various components of the agent’s system.
- langchain: Provides tools and functionalities for integrating various components of LLM applications such as models, data sources, and database solutions. It also provides methods for constructing chat systems, agents, and prompt templates using multiple formats and structuring inputs to LLMs.
- langchain-openai: Python package to use OpenAI models with LangChain.
- langchain-fireworks: Extends the LangChain library by providing solutions specific to the FireworksAI model provider.
- langchain-mongodb: Python package to use MongoDB as a vector store, semantic cache, chat history store, etc. in LangChain.
- arxiv: Python library to download papers from the arXiv repository.
- pymupdf: Enables allowing for the extraction of text, images, and metadata from PDF files.
- datasets: Python library to get access to datasets available on Hugging Face Hub.
- pymongo: Provides methods and functionalities to connect to MongoDB database cluster and perform operations on collections held within databases.
The code snippet below installs all the libraries required for the subsequent implementation steps.

This step covers setting and retrieving environment variables. For this tutorial, the environment variables are API keys and unique identifiers from models and database solution providers. This information is assigned to variables accessed within the development environment.
- Get instructions on how to obtain a MongoDB URI connection string, which is provided right after creating a MongoDB database.
The code snippet above does the following:
- Retrieving the environment variables:
os.environ.get()enables retrieving the value assigned to an environment variable by name reference.
This tutorial uses a specialized subset of the arXiv dataset hosted on MongoDB, derived from the extensive original collection on the Hugging Face platform. This subset version encompasses over 50,000 scientific articles sourced directly from arXiv. Each record in the subset dataset has an embedding field, which encapsulates a 256-dimensional representation of the text derived by combining the authors' names, the abstracts, and the title of each paper.
These embeddings are generated using OpenAI's
text-embedding-3-small model, which was selected primarily due to its minimal dimension size that takes less storage space. Read the tutorial, which explores ways to select appropriate embedding models for various use cases.This dataset will act as the agent's knowledge base. The aim is that before using any internet search tools, the agent will initially attempt to answer a question using its knowledge base or long-term memory, which, in this case, are the arXiv records stored in the MongoDB vector database.
The following step in this section loads the dataset, creates a connection to the database, and ingests the records into the database.
The code below is the implementation step to obtain the subset of the arXiv dataset using the
datasets library from Hugging Face. Before executing the code snippet below, ensure that an HF_TOKEN is present in your development environment; this is the user access token required for authorized access to resources from Hugging Face. Follow the instructions to get the token associated with your account.- Import the pandas library using the namespace
pdfor referencing the library and accessing functionalities. - Import the datasets library to use the
load_datasetmethod, which enables access to datasets hosted on the Hugging Face platform by referencing their path. - Assign the loaded dataset to the variable data.
- Convert the training subset of the dataset to a pandas DataFrame and assign the result to the variable
dataset_df.
Before executing the operations in the following code block below, ensure that you have created a MongoDB database with a collection and have obtained the URI string for the MongoDB database cluster. Creating a database and collection within MongoDB is made simple with MongoDB Atlas. Register a free Atlas account or sign in to your existing Atlas account. Follow the instructions (select Atlas UI as the procedure) to deploy your first cluster.
The database for this tutorial is called
agent_demo and the collection that will hold the records of the arXiv scientific papers metadata and their embeddings is called knowledge.To enable MongoDB's vector search capabilities, a vector index definition must be defined for the field holding the embeddings. Follow the instructions here to create a vector search index. Ensure the name of your vector search index is
vector_index.Your vector search index definition should look something like what is shown below:
Once your database, collection, and vector search index are fully configured, connect to your database and execute data ingestion tasks with just a few lines of code with PyMongo.
- Import the
MongoClientclass from the PyMongo library to enable MongoDB connections in your Python application. - Utilize the MongoClient with your
MONGO_URIto establish a connection to your MongoDB database. ReplaceMONGO_URIwith your actual connection string. - Set your database name to
agent_demoby assigning it to the variableDB_NAME. - Set your collection name to
knowledgeby assigning it to the variableCOLLECTION_NAME. - Access the knowledge collection within the
agent_demodatabase by usingclient.get_database(DB_NAME).get_collection(COLLECTION_NAME)and assigning it to a variable for easy reference. - Define the vector search index name as
vector_indexby assigning it to the variableATLAS_VECTOR_SEARCH_INDEX_NAME, preparing for potential vector-based search operations within your collection.
The code snippet below outlines the ingestion process. First, the collection is emptied to ensure the tutorial is completed with a clean collection. The next step is to convert the pandas DataFrame into a list of dictionaries, and finally, the ingestion process is executed using the
insert_many() method available on the PyMongo collection object.The LangChain open-source library has an interface implementation that communicates between the user query and a data store. This interface is called a retriever.
A retriever is a simple, lightweight interface within the LangChain ecosystem that takes a query string as input and returns a list of documents or records that matches the query based on some similarity measure and score threshold.
The data store for the back end of the retriever for this tutorial will be a vector store enabled by the MongoDB database. The code snippet below shows the implementation required to initialize a MongoDB vector store using the MongoDB connection string and specifying other arguments. The final operation uses the vector store instance as a retriever.
- Start by importing
OpenAIEmbeddingsfrom langchain_openai andMongoDBAtlasVectorSearchfrom langchain_mongodb. These imports will enable you to generate text embeddings and interface with MongoDB Atlas for vector search operations. - Instantiate an
OpenAIEmbeddingsobject by specifying the model parameter as "text-embedding-3-small" and the dimensions as 256. This step prepares the model for generating 256-dimensional vector embeddings from the query passed to the retriever. - Use the
MongoDBAtlasVectorSearch.from_connection_stringmethod to configure the connection to your MongoDB Atlas database. The parameters for this function are as follows:connection_string: This is the actual MongoDB connection string.namespace: Concatenate your database name (DB_NAME) and collection name (COLLECTION_NAME) to form the namespace where the records are stored.embedding: Pass the previously initialized embedding_model as the embedding parameter. Ensure the embedding model specified in this parameter is the same one used to encode the embedding field within the database collection records.index_name: Indicate the name of your vector search index. This index facilitates efficient search operations within the database.text_key: Specify "abstract" as the text_key parameter. This indicates that the abstract field in your documents will be the focus for generating and searching embeddings.
- Create a
retrieverfrom your vector_store using theas_retrievermethod, tailored for semantic similarity searches. This setup enables the retrieval of the top five documents most closely matching the user's query based on vector similarity, using MongoDB's vector search capabilities for efficient document retrieval from your collection.
The agent for this tutorial requires an LLM as its reasoning and parametric knowledge provider. The agent's model provider is Fireworks AI. More specifically, the FireFunction V1 model, which is Fireworks AI's function-calling model, has a context window of 32,768 tokens.
What is function calling?
Function calling refers to the ability of large language models (LLMs) to select and use available tools to complete specific tasks. First, the LLM chooses a tool by a name reference, which, in this context, is a function. It then constructs the appropriate structured input for this function, typically in the JSON schema that contains fields and values corresponding to expected function arguments and their values. This process involves invoking a selected function or an API with the input prepared by the LLM. The result of this function invocation can then be used as input for further processing by the LLM.
Function calling transforms LLMs' conditional probabilistic nature into a predictable and explainable model, mainly because the functions accessible by LLMs are constructed, deterministic, and implemented with input and output constraints.
Fireworks AI's firefunction model is based on Mixtral and is open-source. It integrates with the LangChain library, which abstracts some of the implementation details for function calling with LLMs with tool-calling capabilities. The LangChain library provides an easy interface to integrate and interact with the Fireworks AI function calling model.
The code snippet below initializes the language model with function-calling capabilities. The
Fireworks class is instantiated with a specific model, "accounts/fireworks/models/firefunction-v1," and configured to use a maximum of 256 tokens.That is all there is to configure an LLM for the LangChain agent using Fireworks AI. The agent will be able to select a function from a list of provided functions to complete a task. It generates function input as a structured JSON schema, which can be invoked and the output processed.
At this point, we’ve done the following:
- Ingested data into our knowledge base, which is held in a MongoDB vector database
- Created a retriever object to interface between queries and the vector database
- Configured the LLM for the agent
This step focuses on specifying the tools that the agent can use when attempting to execute operations to achieve its specified objective. The LangChain library has multiple methods of specifying and configuring tools for an agent. In this tutorial, two methods are used:
- Custom tool definition with the
@tooldecorator - LangChain built-in tool creator using the
Toolinterface
LangChain has a collection of Integrated tools to provide your agents with. An agent can leverage multiple tools that are specified during its implementation. When implementing tools for agents using LangChain, it’s essential to configure the model's name and description. The name and description of the tool enable the LLM to know when and how to leverage the tool. Another important note is that LangChain tools generally expect single-string input.
The code snippet below imports the classes and methods required for tool configuration from various LangChain framework modules.
- Import the
tooldecorator fromlangchain.agents. These are used to define and instantiate custom tools within the LangChain framework, which allows the creation of modular and reusable tool components. - Lastly,
create_retriever_toolfromlangchain.tools.retrieveris imported. This method provides the capability of using configured retrievers as tools for an agent. - Import
ArxivLoaderfromlangchain_community.document_loaders. This class provides a document loader specifically designed to fetch and load documents from the arXiv repository.
Once all the classes and methods required to create a tool are imported into the development environment, the next step is to create the tools.
The code snippet below outlines the creation of a tool using the LangChain tool decorator. The main purpose of this tool is to take a query from the user, which can be a search term or, for our specific use case, a term for the basis of research exploration, and then use the
ArxivLoader to extract at least 10 documents that correspond to arXiv papers that match the search query.The
get_metadata_information_from_arxiv returns a list containing the metadata of each document returned by the search. The metadata includes enough information for the LLM to start research exploration or utilize further tools for a more in-depth exploration of a particular paper.To get more information about a specific paper, the
get_information_from_arxiv tool created using the tool decorator returns the full document of a single paper by using the ID of the paper, entered as the input to the tool as the query for the ArxivLoader document loader. The code snippet below provides the implementation steps to create the get_information_from_arxiv tool.The final tool for the agent in this tutorial is the retriever tool. This tool encapsulates the agent's ability to use some form of knowledge base to answer queries initially. This is analogous to humans using previously gained information to answer queries before conducting some search via the internet or alternate information sources.
The
create_retriever_tool takes in three arguments:- retriever: This argument should be an instance of a class derived from BaseRetriever, responsible for the logic behind retrieving documents. In this use case, this is the previously configured retriever that uses MongoDB’s vector database feature.
- name: This is a unique and descriptive name given to the retriever tool. The LLM uses this name to identify the tool, which also indicates its use in searching a knowledge base.
- description: The third parameter provides a detailed description of the tool's purpose. For this tutorial and our use case, the tool acts as the foundational knowledge source for the agent and contains records of research papers from arXiv.
LangChain agents require the specification of tools available for use as a Python list. The code snippet below creates a list named
tools that consists of the three tools created in previous implementation steps.This step in the tutorial specifies the instruction taken to instruct the agent using defined prompts. The content passed into the prompt establishes the agent's execution flow and objective, making prompting the agent a crucial step in ensuring the agent's behaviour and output are as expected.
Constructing prompts for conditioning LLMs and chat models is genuinely an art form. Several prompt methods have emerged in recent years, such as ReAct and chain-of-thought prompt structuring, to amplify LLMs' ability to decompose a problem and act accordingly. The LangChain library turns what could be a troublesome exploration process of prompt engineering into a systematic and programmatic process.
LangChain offers the
ChatPromptTemplate.from_message() class method to construct basic prompts with predefined roles such as "system," "human," and "ai." Each role corresponds to a different speaker type in the chat, allowing for structured dialogues. Placeholders in the message templates (like {name} or {user_input}) are replaced with actual values passed to the invoke() method, which takes a dictionary of variables to be substituted in the template.The prompt template includes a variable to reference the chat history or previous conversation the agent has with other entities, either humans or systems. The
MessagesPlaceholder class provides a flexible way to add and manage historical or contextual chat messages within structured chat prompts.For this tutorial, the "system" role scopes the chat model into the specified role of a helpful research assistant; the chat model, in this case, is FireFunction V1 from Fireworks AI. The code snippet below outlines the steps to implement a structured prompt template with defined roles and variables for user inputs and some form of conversational history record.
The
{agent_scratchpad} represents the short-term memory mechanism of the agent. This is an essential agent component specified in the prompt template. The agent scratchpad is responsible for appending the intermediate steps of the agent operations, thoughts, and actions to the thought component of the prompt. The advantage of this short-term memory mechanism is the maintenance of context and coherence throughout an interaction, including the ability to revisit and revise decisions based on new information.The LangChain and MongoDB integration makes incorporating long-term memory for agents a straightforward implementation process. The code snippet below demonstrates how MongoDB can store and retrieve chat history in an agent system.
LangChain provides the
ConversationBufferMemory interface to store interactions between an LLM and the user within a specified data store, MongoDB, which is used for this tutorial. This interface also provides methods to extract previous interactions and format the stored conversation as a list of messages. The ConversationBufferMemory is the long-term memory component of the agent.The main advantage of long-term memory within an agentic system is to have some form of persistent storage that acts as a state, enhancing the relevance of responses and task execution by using previous interactions. Although using an agent’s scratchpad, which acts as a short-term memory mechanism, is helpful, this temporary state is removed once the conversation ends or another session is started with the agent.
A long-term memory mechanism provides an extensive record of interaction that can be retrieved across multiple interactions occurring at various times. Therefore, whenever the agent is invoked to execute a task, it’s also provided with a recollection of previous interactions.
- The function
get_session_historytakes asession_idas input and returns an instance ofMongoDBChatMessageHistory. This instance is configured with a MongoDB URI (MONGO_URI), the session ID, the database name (DB_NAME), and the collection name (history). - A
ConversationBufferMemoryinstance is created and assigned to the variable memory. This instance is specifically designed to keep track of the chat_history. - The chat_memory parameter of ConversationBufferMemory is set using the
get_session_historyfunction, which means the chat history is loaded from MongoDB based on the specified session ID ("my-session").
This setup allows for the dynamic retrieval of chat history for a given session, using MongoDB as the agent’s vector store back end.
This is a crucial implementation step in this tutorial. This step covers the creation of your agent and configuring its brain, which is the LLM, the tools available for task execution, and the objective prompt that targets the agents for the completion of a specific task or objective. This section also covers the initialization of a LangChain runtime interface,
AgentExecutor, that enables the execution of the agents with configured properties such as memory and error handling.- The
create_tool_calling_agentfunction initializes an agent by specifying a language model (llm), a set of tools (tools), and a prompt template (prompt). This agent is designed to interact based on the structured prompt and leverage external tools within their operational framework. - An
AgentExecutorinstance is created with the Tool Calling agent. TheAgentExecutorclass is responsible for managing the agent's execution, facilitating interaction with inputs, and intermediary steps such as error handling and logging. TheAgentExecutoris also responsible for creating a recursive environment for the agent to be executed, and it passes the output of a previous iteration as input to the next iteration of the agent's execution.- agent: The Tool Calling agent
- tools: A sequence of tools that the agent can use. These tools are predefined abilities or integrations that augment the agent's capabilities.
- handle_parsing_errors: Ensure the agent handles parsing errors gracefully. This enhances the agent's robustness by allowing it to recover from or ignore errors in parsing inputs or outputs.
- memory: Specifies the memory mechanism the agent uses to remember past interactions or data. This integration provides the agent additional context or historical interaction to ensure ongoing interactions are relevant and grounded in relative truth.
The previous steps created the agent, prompted it, and initiated a runtime interface for its execution. This final implementation step covers the method to start the agent's execution and its processes.
In the LangChain framework, native objects such as models, retrievers, and prompt templates inherit the
Runnable protocol. This protocol endows the LangChain native components with the capability to perform their internal operations. Objects implementing the Runnable protocol are recognized as runnable and introduce additional methods for initiating their process execution through a .invoke() method, modifying their behaviour, logging their internal configuration, and more.The agent executor developed in this tutorial exemplifies a Runnable object. We use the
.invoke() method on the AgentExecutor object to call the agent. The agent executor initialized it with a string input in the example code provided. This input is used as the {input} in the question component of the template or the agent's prompt.In the first initial invocation of the agent, the ideal steps would be as follows:
- The agent uses the retriever tool to access its inherent knowledge base and check for research papers that are semantically similar to the user input/instruction using vector search enabled by MongoDB Atlas.
- If the agent retrieves research papers from its knowledge base, it will provide it as its response.
- If the agent doesn’t find research papers from its knowledge base, it should use the
get_metadata_information_from_arxiv()tool to retrieve a list of documents that match the term in the user input and return it as its response.
This next agent invocation demonstrates the agent's ability to reference conversational history, which is retrieved from the MongoDB database from the
chat_history collection and used as input into the model.In the second invocation of the agent, the ideal outcome would be as follows:
- The agent references research papers in its history or short-term memory and recalls the details of the first paper on the list.
- The agent uses the details of the first research paper on the list as input to the
get_information_from_arxiv()tool to extract the abstract of the query paper.
This tutorial has guided you through building an AI research assistant agent, leveraging tools such as MongoDB, Fireworks AI, and LangChain. It’s shown how these technologies combine to create a sophisticated agent capable of assisting researchers by effectively managing and retrieving information from an extensive database of research papers.
Or, if you simply want to get a well-rounded understanding of the AI Stack in the GenAI era, read this piece.
- What is an Agent? An agent is an artificial computational entity with an awareness of its environment. It is equipped with faculties that enable perception through input, action through tool use, and cognitive abilities through foundation models backed by long-term and short-term memory. Within AI, agents are artificial entities that can make intelligent decisions followed by actions based on environmental perception, enabled by large language models.
- What is the primary function of MongoDB in the AI agent? MongoDB serves as the memory provider for the agent, storing conversational history, vector embedding data, and operational data. It supports information retrieval through its vector database capabilities, enabling semantic searches between user queries and stored data.
- How does Fireworks AI enhance the functionality of the agent? Fireworks AI, through its FireFunction V1 model, enables the agent to generate responses to user queries and decide when to use specific tools by providing a structured input for the available tools.
- What are some key characteristics of AI agents? Agents are autonomous, introspective, proactive, reactive, and interactive. They can independently plan and reason, respond to stimuli with advanced methodologies, and interact dynamically within their environments.